Clustering MS Spectre
GRAD CHALLENGE 3 (CLUSTERING MS SPECTRA): Read in a .mgf file (example here)
containing many thousand MS/MS spectra. Look only at the fragmentation peaks (not any precursor information). Discretize into m/z bins (by rounding) of 0.01 Th and cluster together the mass spectra.
Your goals are (1) for each cluster has spectra that are not far from one another (using L2 distance) and
(2) for spectra in different clusters are far from one another (using L2 distance).
Your program will accept one argument, the name of the .mgf file. Your program will print the clusters by referring to the indices of the spectra in the .mgf file on the same line. For example, the output
|
0 1 3 8 2 4 5 6 7 9 |
 |
has clusters {0,1,3,8}, {2,4,5}, {6,7}, and {9}. Distance between spectrum 0 and spectrum 1 will penalize this result, while distance between spectrum 0 and spectrum 2 will reward this result. Spectra unassigned to a cluster will be put into cluster 0. The winner will be selected by an F-test. Your code must run in less than 10 minutes on several thousand spectra (with # peaks roughly equal to one of the example spectra above). Deviate from the output format at your own risk.
Make your code from scratch with no imported libraries (exception: C++ code may use the standard library and python may use numpy). C++ entries will be compiled using the flags specified above.
Implementation
Locality Sensitive Hashing (LSH)
Sample input: spectre.mgf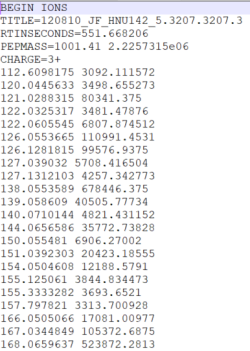 |  |